In today’s data-driven world, handling large datasets efficiently is a major challenge for programmers and data scientists. Many rely on Pandas for data manipulation, but as datasets grow into millions or even billions of rows, Pandas quickly becomes a bottleneck. Since it loads all data into memory, it can cause slow performance, crashes, or excessive RAM usage—making it impractical for large-scale data processing.
Traditional alternatives, like SQL databases or Spark, require significant configuration and may not integrate seamlessly with Python’s ecosystem. This leaves developers searching for a scalable, yet Pythonic solution to process big data efficiently.
Enter Dask: The Power of Parallel Processing
Dask is a game-changer. It extends the capabilities of Pandas and NumPy by enabling parallel and distributed computing, allowing you to process massive datasets efficiently—without changing much of your existing code. Unlike Pandas, which processes data in-memory, Dask breaks large datasets into smaller chunks and processes them in parallel, making it possible to work with datasets that exceed your RAM limitations.
Whether you’re analyzing financial records, processing scientific data, or training machine learning models, Dask provides the speed and scalability you need—while maintaining the simplicity of Python.
Dask: The Ultimate Solution for Handling Big Data in Python
As data continues to grow exponentially, developers and data scientists face significant challenges when using tools like Pandas and NumPy. While these libraries are powerful for data analysis, they require loading the entire dataset into memory, making them inefficient when dealing with large datasets that exceed the system’s RAM.
This is where Dask comes in—a Python library designed to handle big data efficiently by enabling parallel and distributed computing. It provides a scalable solution that seamlessly integrates with existing Python tools while optimizing memory usage and computation speed.
The History and Evolution of Dask
Dask was first introduced in 2014 by Matthew Rocklin and the team at Continuum Analytics (now Anaconda, Inc). The goal was to create a tool that could extend Pandas and NumPy to work with datasets larger than memory.
🔹 Key Milestones in Dask’s Development
- 2014-2015: Initial release with basic support for parallel computing.
- 2016-2017: Improved integration with Pandas, NumPy, and Jupyter notebooks.
- 2018-2020: Enhanced distributed computing features, making it easier to run Dask on cloud platforms and multi-core machines.
- 2021-Present: Expanded support for machine learning, cloud computing, and real-time data processing.
Today, Dask has become an essential tool in the Python ecosystem, widely used in fields like data science, finance, machine learning, and scientific computing.
🔍 What is Dask?
Dask is a flexible parallel computing library that enables users to scale their computations from a single laptop to a multi-node cluster. Unlike traditional Python libraries that process data sequentially, Dask divides large datasets into smaller chunks and processes them in parallel, significantly improving performance.
How is Dask Different from Pandas and NumPy?
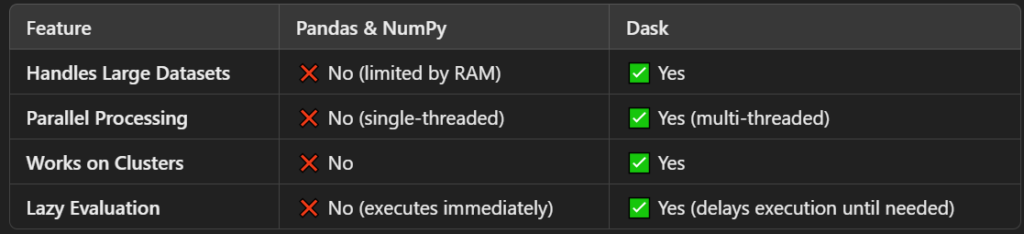
Core Components of Dask
Dask provides several high-level APIs that mimic existing Python libraries while enabling parallel and distributed computing.
1️⃣ Dask DataFrame: Large-Scale Pandas Alternative
Dask DataFrame functions just like Pandas, but instead of loading an entire dataset into memory, it splits the data into smaller partitions and processes them in parallel.
🔹 Example: Handling Large CSV Files Efficiently
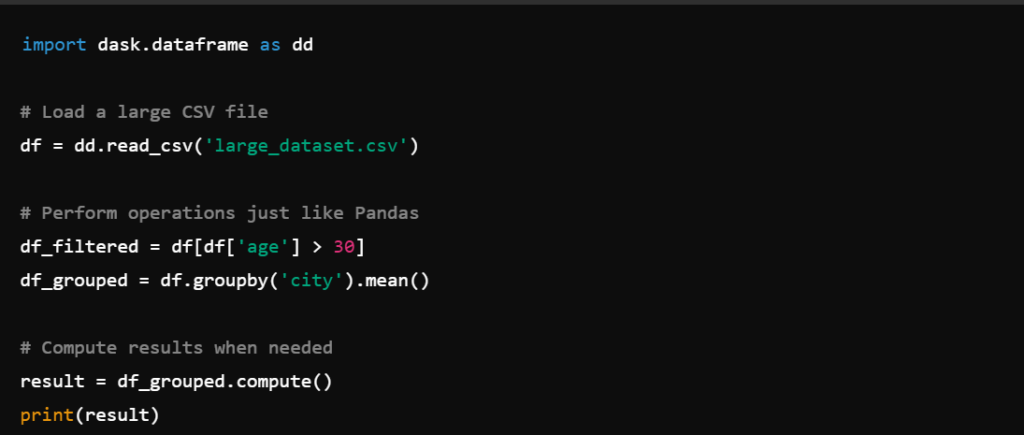
Unlike Pandas, Dask doesn’t execute operations immediately, allowing it to handle large files efficiently.
2️⃣ Dask Array: Scalable NumPy for Large-Scale Computations
Dask Array is designed for large numerical computations, similar to NumPy but optimized for parallel execution. It is widely used in scientific computing, AI, and simulations.
🔹 Example: Working with Large Matrices
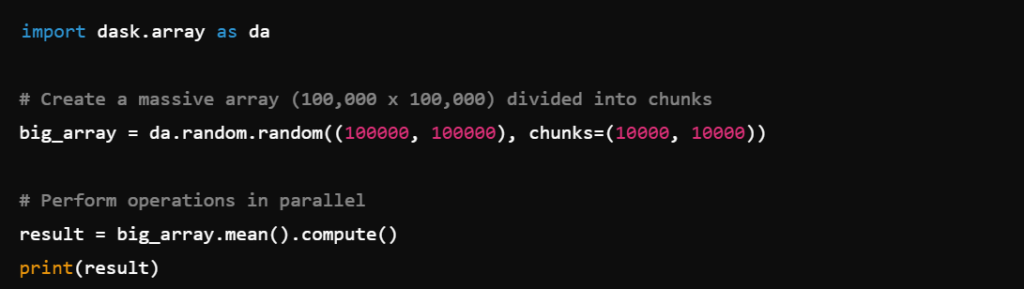
Dask Array makes it possible to perform computations on large datasets without exceeding memory limits.
3️⃣ Dask Bag: Processing Unstructured Data
Dask Bag is useful for handling unstructured or semi-structured data, such as JSON files, log files, and text-based datasets. It is similar to Python’s built-in lists but optimized for parallel processing.
🔹 Example: Processing a Large JSON File
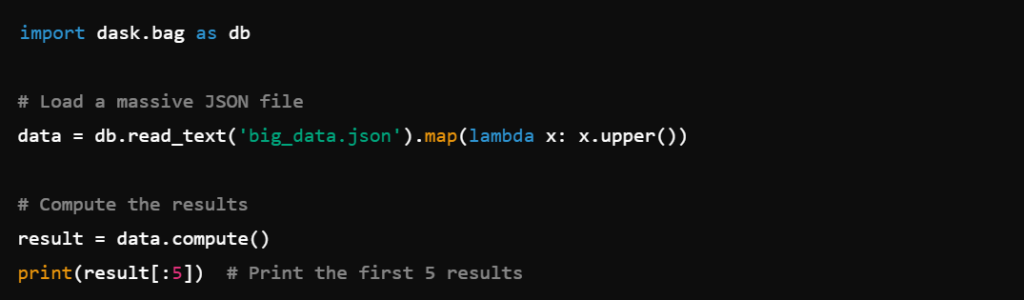
This is particularly useful when dealing with large-scale text data processing.
4️⃣ Dask Distributed: Running Dask on a Cluster
Dask supports distributed computing, allowing it to run across multiple machines or cloud environments like AWS, Google Cloud, and Azure.
🔹 Example: Running Dask on Multiple Cores
This feature allows scaling computations across multiple machines, making it ideal for big data applications.
Key Advantages of Dask
✔ Seamless Integration → Works with Pandas, NumPy, Scikit-Learn, TensorFlow, and more.
✔ Handles Big Data → Processes datasets larger than memory efficiently.
✔ Parallel Execution → Runs computations on multiple CPU cores or even clusters.
✔ Cloud & Cluster Support → Works on AWS, Google Cloud, and Kubernetes.
✔ Lazy Evaluation → Optimizes execution by delaying computations until needed.





